
Key takeaways
- GoDaddy uses a hybrid approach combining human and LLM evaluations to maintain the integrity and scalability of LLM assessments.
- Innovations such as synthetic dialog generation and automated LLM reviews have significantly improved the efficiency of the evaluation process.
- The LLM evaluation workbench has enabled cost savings and improved AI governance by providing data-driven insights into model capabilities.
(Editor's note: This post is the third in a three part series that discusses why and how we created and implemented an evaluation model for LLMs that GoDaddy uses when creating GenAI applications. You can read part one here and part two here.)
Industry trends in LLM model evaluation
A growing list of LLM evaluation options are now available in the industry. We continue to actively monitor their features to understand how we can adapt and improve our evaluation process.
The use of public benchmarks comes with some drawbacks. Since the evaluation criteria are public, the evaluation criteria can (and do) end up being fed as training data to the new models under development. This can skew the test results since the models will overfit and be able to deliver outsized performance and reduce the potency of the benchmark to be an indicator of the model’s capabilities. Since our tests are not in the public domain, they continue to provide us with high quality signals on LLM model evaluation. In the next section we delve into the pros and cons of automating Human-in-the-loop reviews with LLMs.
Human vs. LLM as judge
This is an area of active research and development. Should we use human judges for LLM model evaluation as an integral part or not? Due to the rapid advances in LLM capability the boundary line of when to use humans vs. LLMs as judges continues to shift frequently. There are pros and cons with these approaches which the following table lays out:
| Human as judge | LLM as judge | |
|---|---|---|
| Human toil | Involves human toil, there is reasonable effort involved in forming a panel of human judges, guiding them and then spending their time in doing the evaluation. | Aside from the cost of initial setup, LLM as a judge does not demand human toil. The initial setup cost can be non-trivial as we need to evaluate which LLM can perform the role of the LLM as a judge. |
| Scalability | It is difficult to scale human reviewers as we try to keep pace with the number of LLMs being released. | LLM as judge can scale comfortably with the number of LLMs being released. |
| Test Contamination | The chances of model training being contaminated with evaluation criteria is lower since there is inherent variability in human evaluation criteria. | There are higher chances of models being contaminated since these test evaluation criteria can get released and then inducted into the model training stream for future model releases thereby skewing performance results. |
| Bias | Human judges can have cultural and stereotypical bias which may influence their ability to judge objectively. Human judges are susceptible to show familiarity bias and confirmation bias when evaluating the LLMs responses. | LLM judges can reflect the biases they have picked up in training data. In addition, they may show bias on evaluation if they have not been trained on similar scenarios themselves. |
| Specialized topics | When grading LLMs on specialized topics, we can rely on the help of domain experts in legal, medical, financial, science, and engineering. However, gathering the requisite specialized resources and setting up evaluation criteria can involve significant amounts of effort. The benefit is that the evaluation can give a high signal to noise ratio to help understand the model capabilities. | Generalized LLMs can give a promising signal on specialized topic evaluation of the candidate LLM, but the approach is prone to the same issue we are trying to evaluate (has the LLM judge been evaluated to be very good with the specialized topic it is helping evaluate for the candidate LLM?)! It is possible to have LLMs to have domain expertise to evaluate on those specific domains, but that requires a substantial investment to train and maintain those specialized LLMs in the first place. |
| Subjectivity | Human judgement can be subjective and varying. When evaluating an LLM response, different humans can have differing judgement calls on the same response. Worse, the same human judge can be prone to answering the same evaluation differently based on nonfunctional criteria such as the order of the answers (positional bias) or tone of the response and so on. | Subjectivity can be an issue with LLM as a judge. Depending on the LLM (chosen as judge) the evaluation of the same response can vary. In addition, the LLM as a judge may show variation due to its model settings such as temperature, topP, and topK. LLMs are known to have positional bias if the order of the questions is changed and model is evaluating multiple answers in the same call. |
Should LLMs be judges?
From a philosophical point of view, there are divergent views on the fitness of the LLM as a judge approach. Various benchmarks like PromptBench and RedEval have adopted LLM as a judge approach for better scaling via evaluation automation. However, using LLM as judge may cut the essential human signal out of the loop causing crossbreeding-like effects (LLMs learning from evaluation of LLM judges) which could result in model collapse. Later, we will cover how we have used a hybrid approach to gain the benefit of automation while not totally cutting the human out of the loop, thereby getting a good balance of benefits from both approaches.
Innovations
In the following sections, we'll cover some of the innovations we built into the LLM evaluation workbench.
Visualization
We drive the details of our visualization via an example of the GPT-4o mini model card we generated. We initially started off by generating static reports for each model evaluation in our internal Confluence pages. However, it became clear this made it harder for our users to interact with the results. So the engineering team innovated to build a Streamlit app which allowed for an interactive experience for the end user.
The following image shows the initial page, where we provide the user with the ability to choose one of our published models:
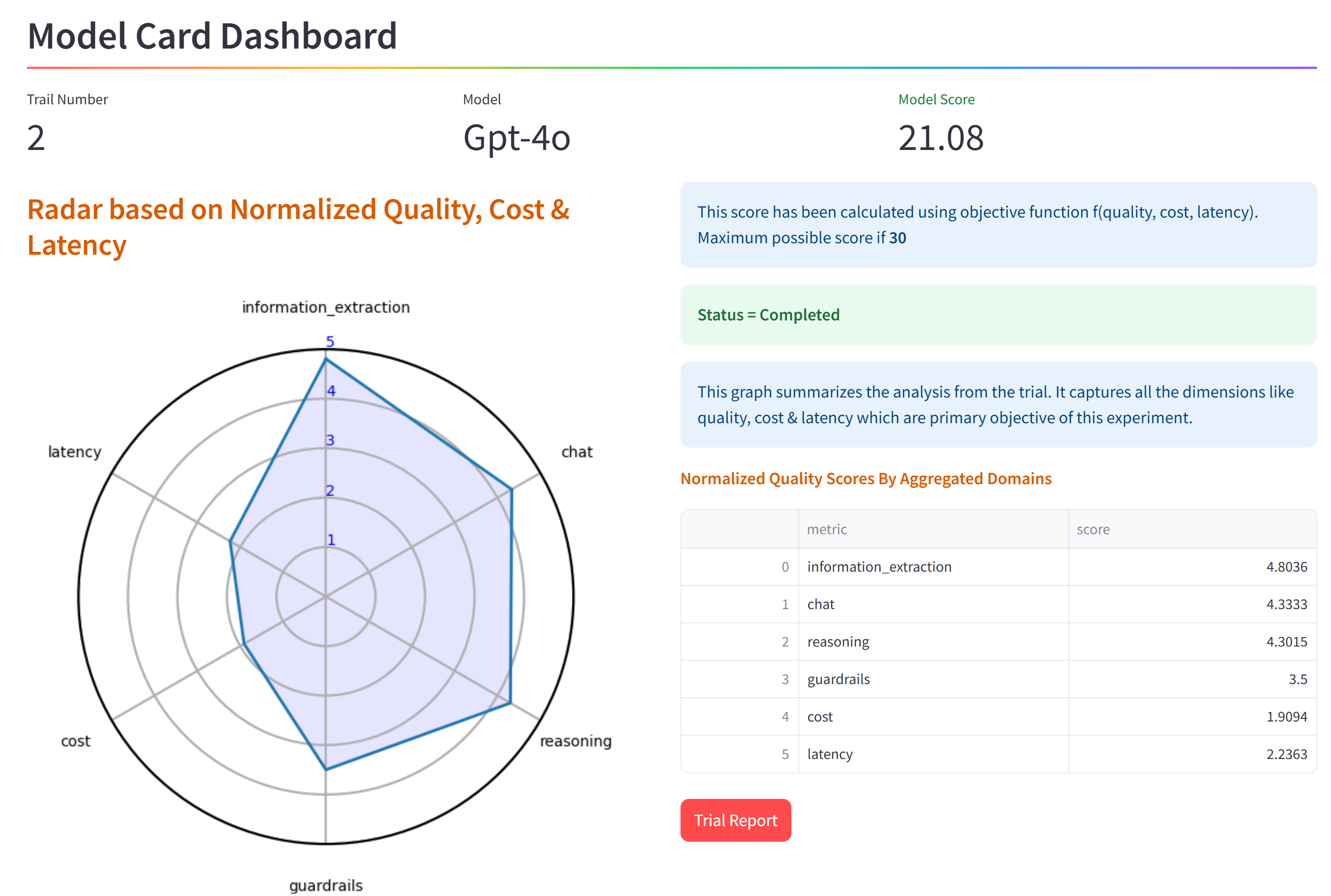
Upon choosing a model card, we display a summary of the model evaluation. The user gets a quick view into the model capabilities. On the top we mention the model name and the model score [objective function score (OFS)] which helps quickly summarize the model's capabilities. A radar chart graphically shows relative strengths and weaknesses among the 6 categories we mentioned earlier. A table view of the same is shown to display category normalized quality scoresin detail. The following image shows the summary of the model evaluation displayed to the user:
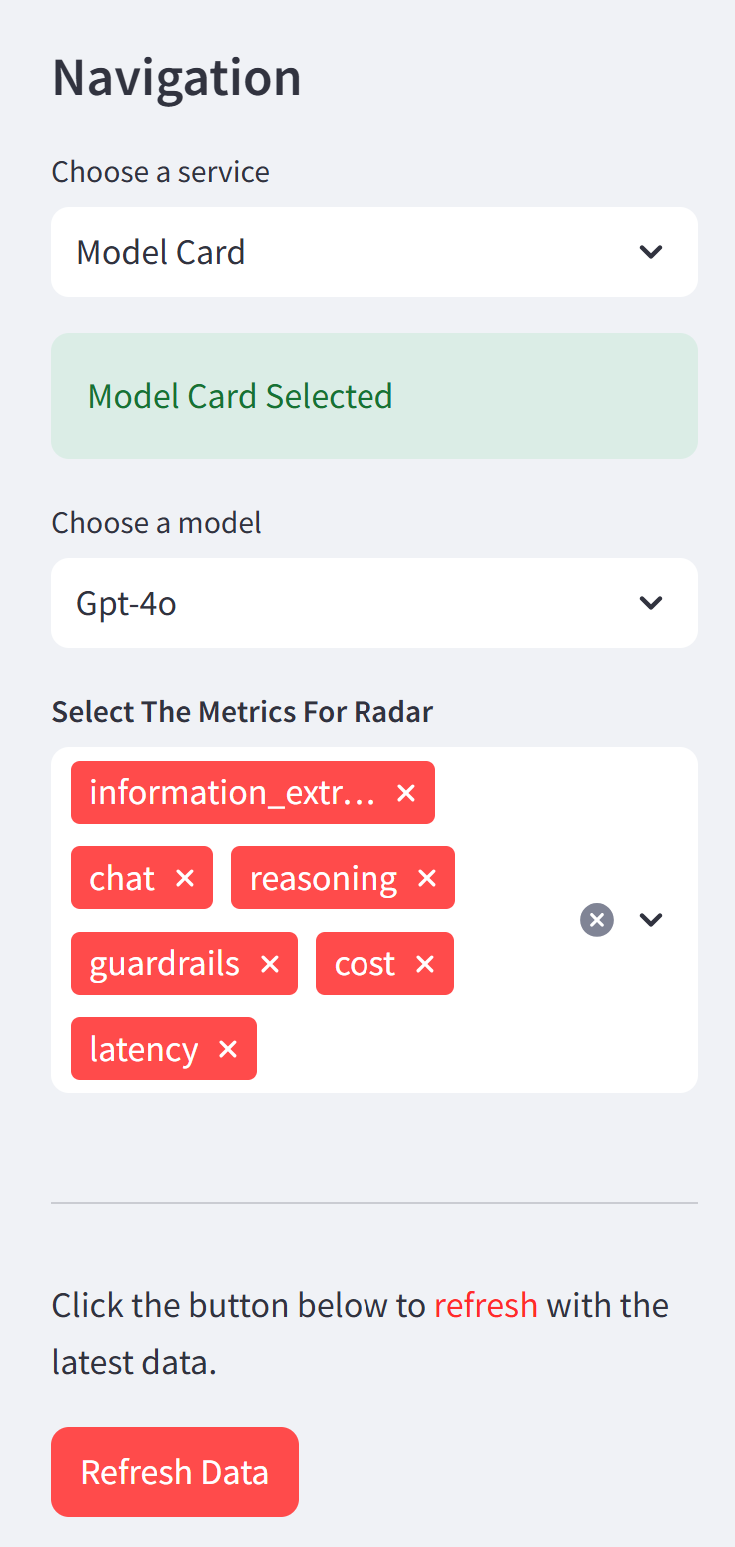
The following card allows users to choose which categories among the six available ones need to be included or excluded to allow them to focus on metrics of concern on the navigation bar:
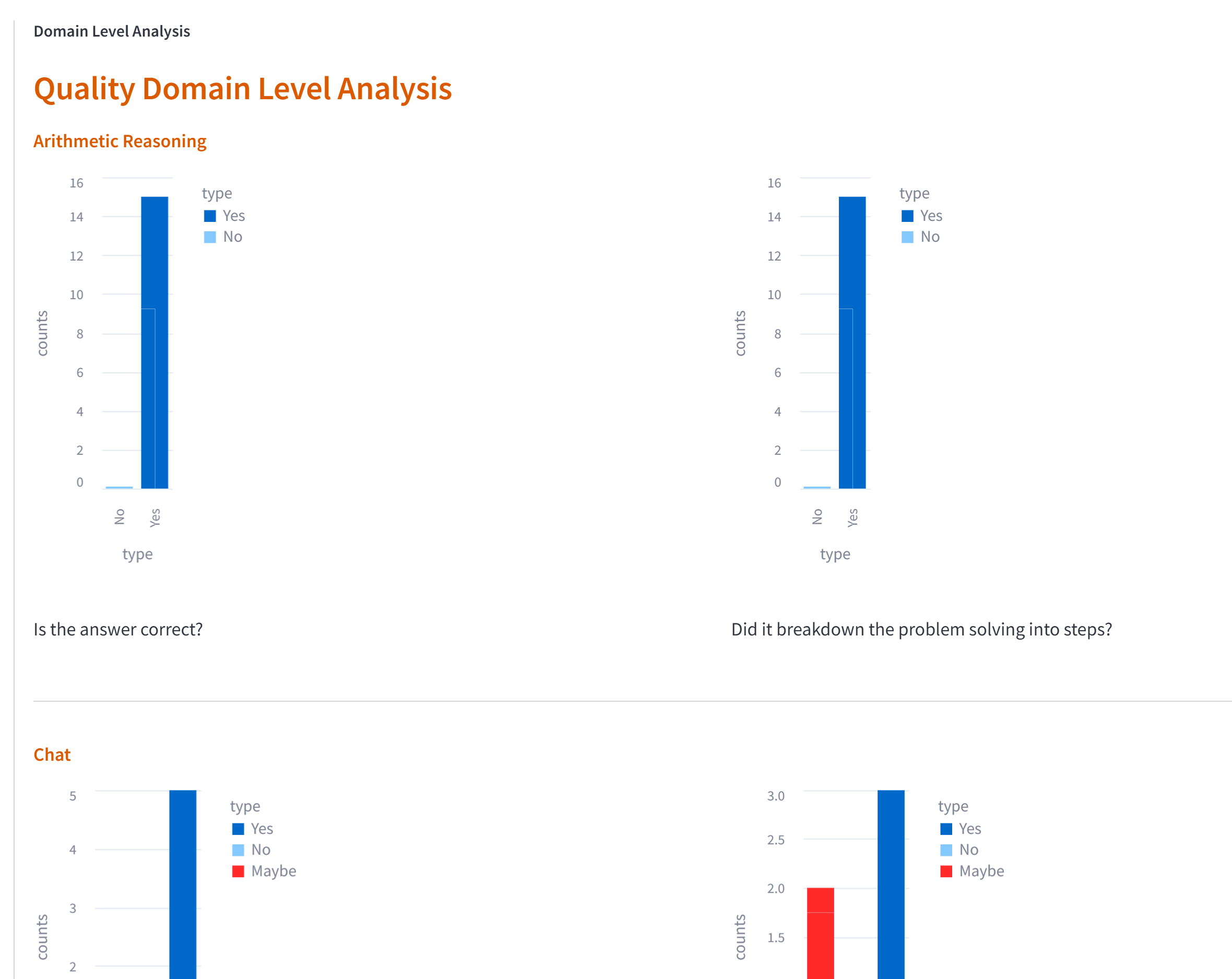
The visualization dashboard is updated live based on the user’s input. Later on the page, we provide controls to roll out the metrics for each category in detail. The list of questions asked to the evaluator is shown to allow for detailed drill down analysis as desired. The following image displays these features:
Next, we discuss how we innovated on synthetic dialog generation for evaluating an LLMs chat capabilities.
Synthetic dialog generation with agents
One of the criteria we evaluate is the chat capability of an LLM. GoDaddy’s agent products are critically dependent on the good conversation ability of an LLM to power our product and support chatbots. While the chatbot application teams have done an excellent job of creating interactive, helpful chatbots, they've been challenged to upgrade to newer, more capable LLMs in the market. The prerequisite for that is to ensure the new contender model has equivalent or better chat performance than the incumbent. Our partner teams helped us with sharing typical dialogs between the customer and current incumbent LLM model. In order to do a comparative performance, we need to generate the dialog with the contender model for the same scenario with the real customer. Generating dialogues with real customers was a non-starter because we could not afford to cause a degraded customer experience by exposing a relatively untested LLM to the public.
The team brainstormed the challenge and came up with a creative solution of generating such data synthetically by powering both sides of the dialog with LLMs. We thus created suitable agents which represented the customer and customer support personas appropriately.
For example, the customer agent’s persona was set with the following descriptive prompt (for illustrative purposes, details elided):
Act as a business owner. You are the owner of a small business that sells toys. You have a store. You've heard about GoDaddy Payments … You are not technically savvy when it comes to computers and technology, unless they are toy related.
Similarly, the GoDaddy support agent's persona was set with the following descriptive prompt (for illustrative purposes, details elided):
Act as a chatbot for GoDaddy. Customers will interact with you over chat. You’re to help the customer reach a solution. You’re an expert in both sales and troubleshooting on all GoDaddy products and services. Your personality is a mixture of empathetic, friendly, energizing, forward-thinking, and supportive …
We primed the objective for the customer agent with a scenario where a customer is looking for help to GoDaddy’s innovative payment processing solution. Then we let the agents converse with each other and recorded the generated dialog. We reviewed these dialogs with the GoDaddy Support (Care) team and tweaked them to ensure that good fidelity was achieved and that the dialogs were a good representation of how dialogs happened in real situations.
This innovative approach of leveraging multiagent dynamics for synthetic dialog generation helped us scale the LLM evaluation to the velocity of new LLMs released in the market.
Automated review of LLM performance
We got a high fidelity LLM evaluation data based on Human-in-the-loop reviews. However, a major challenge with Human-in-the-loop the ability to scale. LLMs continue to be released into the market at a rapid pace. Our scaling for human reviews is limited by human reviewer availability as well as the amount of time a human reviewer can dedicate for such reviews. We have already stated in a previous section the philosophical ambiguity around a LLM being able to judge other LLMs. However, this does not block us from automating reviews for questions where the answer is a crisp number (for mathematical reasoning puzzles) or is in a binary category (questions where the answer is yes or no). So the team worked on automating reviews of such responses in a systematic manner. We started with questions in well-defined domains such as mathematical reasoning where there is a clear answer expected. For example:
Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
The correct answer is 11. To automate this evaluation, we induced the LLM to separate out the answer and the explanation into distinct sections with appropriate prompting:
Specify response with answer and explanation:
This induces the LLM to respond with the answer and explanation in distinct sections. We then post process this output with another LLM judge which is asked to parse out the answer and explanation separately via a tool call. Finally, we get output from our LLM judge in a structured tool invoke format, that allows us to unambiguously evaluate the actual and expected responses in a programmatic manner.
We were able to automate the verification of correctness of response as mentioned above. We were also able to automate review of the qualitative aspects of the LLM responses. Consider the following question and expected answer for evaluating the the information extraction capability of the LLM:
Answer the question based on the context below. The response to the question should be concise.
Context: Beyonce Giselle Knowles-Carter is an American singer, songwriter, record producer and actress. She performed in various singing and dancing competitions as a child, and rose to fame in the late 1990s as lead singer of R&B girl-group Destiny’s Child. Managed by her father, Mathew Knowles, the group became one of the world’s best-selling girl groups of all time. Their hiatus saw the release of Beyonce’s debut album, Dangerously in Love, which established her as a solo artist worldwide, earned five Grammy Awards and featured the Billboard Hot 100 number-one singles "Crazy in Love" and "Baby Boy".
Question: What areas did Beyonce compete in when she was growing up?
The expected answer to this question is “singing and dancing.”
In this case we already had human curated answers in our question bank. We simply prompted our LLM judge to output "yes" or "no" to the question of whether the LLM response and the expected responses were similar.
By using scrappy and innovative approaches such as these, the team overachieved and automated about 70% of the reviews compared to our original target of 30%! This not only allowed us to speed up our reviews but also reduced our human reviewer toil by more than 50% on average. We continue to probe for opportunities to automate further by looking at emerging research and discussion in the LLM-as-a-judge space.
Next, we look at the benefits accrued due to the adoption of standardized evals for LLMs using the workbench.
Benefits of the LLM evaluation workbench
Since the advent of the LLM evaluation workbench we have been able to evaluate numerous popular LLM models. In a data driven manner, we can vouch for our intuitions about the model. It brought convergence on understanding LLM capabilities and has allowed for teams with critical workflows to switch models in a scientific data driven manner.
Significant cost efficiency
For example, the LLM evaluation workbench showed that Claude 3 Sonnet (contender) performed admirably in comparison to GPT 4 (incumbent). While Claude 3 Sonnet did not exceed the performance of GPT 4 in various dimensions of chat capabilities such as number of chats turns, ability to resolve customer’s issue, or friendliness of tone, it came in very close in performance. In addition, it was able to get this performance at 75% cost savings over GPT 4! This has unlocked the potential for huge cost savings, while minimizing the risk of regression in customer satisfaction metrics.
Shift-left on AI governance
GoDaddy has placed a huge emphasis on safe governed use of GenAI technology. The LLM evaluation workbench now collects metrics on an LLM's vulnerabilities with regards to jailbreaking and hallucination. This has revealed some interesting weaknesses in some of the popular models. We now output a guardrails score for LLMs which ranges from 0 (worst) to 5 (best). This sets the stage for governance guidelines which require GenAI apps to have a minimum guardrail score of 4 out 5 and thus raise the bar on safe AI use.
A gamified approach to GenAI adoption
The LLM evaluation workbench now delivers the OFS for the LLM model as well as the fine-grained scores for each category. This allows us to gamify the adoption of good, cost efficient, and safe LLMs for adoption in GenAI apps across GoDaddy. Additionally, it removes certain historical biases which exist in model choice such as the proclivity to choose a version of GPT and ignore other choices. Now GenAI app developers can have a more nuanced and balanced view to leverage the larger ecosystem of LLMs available from various model providers such as Amazon, Anthropic, Cohere, and Google. This ensures a healthy distribution of model use and guards against the vulnerability of being a monoculture in terms of LLM model use. Developers can now select a LLM that best fits their specific GenAI app in a data driven manner.
Future work
We have done path breaking work in terms of moving up the GenAI maturity levels. However, LLM innovations continue to happen at a furious pace. The scope for continuing to enhance the LLM evaluation workbench to cover an ever-increasing number of LLM capabilities is quite evident. The following indicative directions are how we would like to evolve in the LLM evaluation space:
- Continue to explore and exploit increased automation of the LLM review process and asymptotically aspire to reach 100% automation.
- Continue to refine the current question set to accommodate the ever-improving performance of the LLMs. As the baseline performance of these LLMs continue to trend upward, we need to revise the criteria to ensure that there is no saturation on the generated score and the objective function score continues to have sufficient discriminative power.
- Evaluate function calling and structured JSON response capabilities of LLMs.
- Support evaluation of multimodal models which are capable to taking images, video, and sound as input or output.
- Evaluate groundedness and relevancy of the LLM’s response.
Acknowledgements
The groundbreaking work for the LLM evaluation workbench is the result of tireless work by our dedicated GoDaddy engineers. I would like to thank Harsh Dubey, Isabel You, and Daniyal Rana for scrappily building out the LLM evaluation workbench with an eye on Agile feature delivery.
I would like to thank Ramji Chandrasekaran, Harsh Pathak, Tiago Pellegrini, Nora Wang, Sid Pillay, and Jing Xi for their expertise in curating the evaluation criteria and their enthusiastic participation as reviewers.
Finally, I would like to thank Richard Clayton, Thomas Hansen, and Jordan Lynch from the Care team for their great input as stakeholders who provided the requirements for the LLM evaluation workbench for their participation as reviewers.





