
GoDaddy is a platform dedicated to supporting entrepreneurs and small businesses by providing them with the necessary tools and resources to succeed online. With a customer base of over 20+ million individuals and businesses worldwide, GoDaddy serves as the go-to destination for individuals seeking to establish a professional online presence, attract customers, and manage their work efficiently.
The GoDaddy Data Platform team is driven by a commitment to using data to drive meaningful business decisions and improve customer experience. In 2018, the company undertook a major infrastructure revamp and partnered with Amazon Web Services (AWS) to enhance its capabilities and meet the needs of its rapidly growing customer base. The Data Platform team aimed to establish a well-defined data strategy and decentralized data ownership and processing to ensure long-term success for the company.
As part of team’s mission to build a low-cost cloud data platform, the team implemented a platform which is scalable, reliable, cost-effective, secure, customer-centric, and well-governed.
Over past few years, the Unified Data Platform’s implementation aligns with the team’s mission to build a low-cost cloud data platform that meets the needs of its customers. By prioritizing scalability, reliability, cost-effectiveness, security, and governance, the platform is well-equipped to support the growing demands and requirements of its users. By being customer-centric, the platform is designed to meet the specific needs and preferences of its users, ensuring a high level of satisfaction and value. With these qualities in place, the platform is poised to deliver a robust and efficient data solution that is both accessible and affordable.
This technical blog provides an in-depth look at the evolution of data at GoDaddy, highlighting the challenges faced along the way and the journey towards building a modern, low-cost cloud data platform. The blog covers the early days of data at GoDaddy, including the initial challenges faced in managing and leveraging data effectively.
Through this blog, readers will gain a deeper understanding of the key considerations and best practices for building a successful cloud data platform. By sharing the lessons learned and experiences from the journey at GoDaddy, this blog aims to provide valuable insights and guidance for organizations embarking on a similar journey.
Phase I: SQL Server BI Platform (2000–2012)
GoDaddy’s data platform journey began with Microsoft SQL Server BI (MSBI) stack, including SQL Server reporting services (SSRS), SQL Server Analytical Services (BI Cube), and SSIS for orchestration services. Combining the MSBI SQL stack with .NET web service for data visualization helped GoDaddy’s revenue grow by almost a billion dollars.
As our product offerings grew, maintaining complex relationships using relational databases became challenging. Relational servers couldn’t be scaled up anymore, which led us to scale horizontally by adding more MySQL and MSSQL servers. Modeling new domains and making them available for consumption across the company started to take longer. Having a consistent pattern for making schema changes across our different domains and business units became increasingly complex which led to brittle downstream pipelines processing data for reporting and analysis. It was time to look for a new solution.
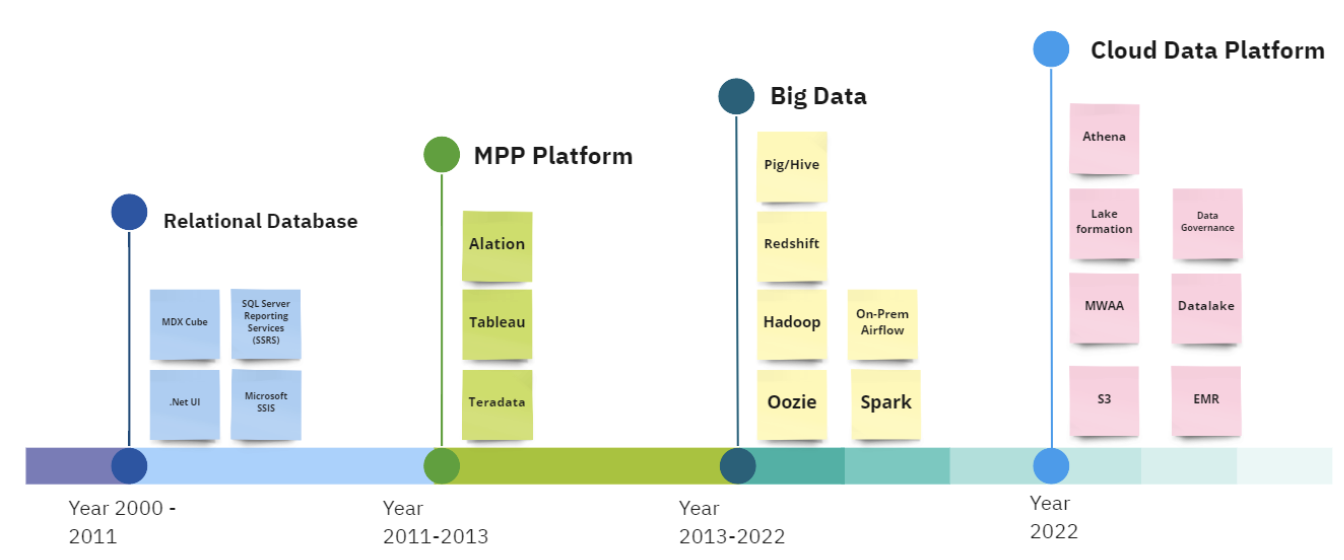
Phase II: Move to BigData world (2013–2021)
Because of our growth, we had to select a better solution. We chose Hadoop a scalable and dependable platform for big data processing. It offers cost-effectiveness and efficiency by allowing storage and processing of large amounts of data on standard hardware, making it a promising technology option for GoDaddy. There was a central team that would handle maintaining the cluster including putting guard rails to prevent one user or job from hogging resources on the entire cluster. Some teams wrote custom map-reduce jobs, while others used higher-level languages such as Pig and Hive to develop their data pipelines.
The initial challenge in adopting Hadoop was transferring data from various sources into the Hadoop file system. The lack of a standard pattern or solution for schema versioning resulted in downstream consumers being affected. To overcome this, GoDaddy adopted a decentralized approach by allowing data producers to publish data directly into Hadoop Distributed File System (HDFS) with minimal restrictions. This approach made data accessible and self-managed by individual teams but centralized data from different domains in one location. We also used Redshift as backend for interactive reporting via Tableau. The GoDaddy Hadoop cluster grew to over a petabyte in storage, with 800+ nodes serving as the central computing platform for GoDaddy. However, as the data size and number of users grew, the lack of governance and security control led to problems with data ownership and governance. These challenges taught us a good lesson we carried over in our planning to migrate to AWS.
Phase III: Hadoop Migration and beginning the journey to the cloud
For over a decade, we ran our Hadoop infrastructure and it further helped grow the business and add customers through faster insights. As our business saw explosive growth, so did our data volumes. The Hadoop environment became hard to manage and govern. As the teams grew, copies of data started to grow in the HDFS. Several teams started to build tooling to manage this challenge independently, duplicating efforts. Managing permissions on these data assets became harder. Making data discoverable across a growing number of data catalogs and systems had started to become a big challenge. Although the cost of storage these days is relatively inexpensive, when several copies of the same data asset are available, it’s harder for analysts to use the data efficiently and reliably. Business analysts need robust pipelines on key datasets that they rely on to make business decisions.
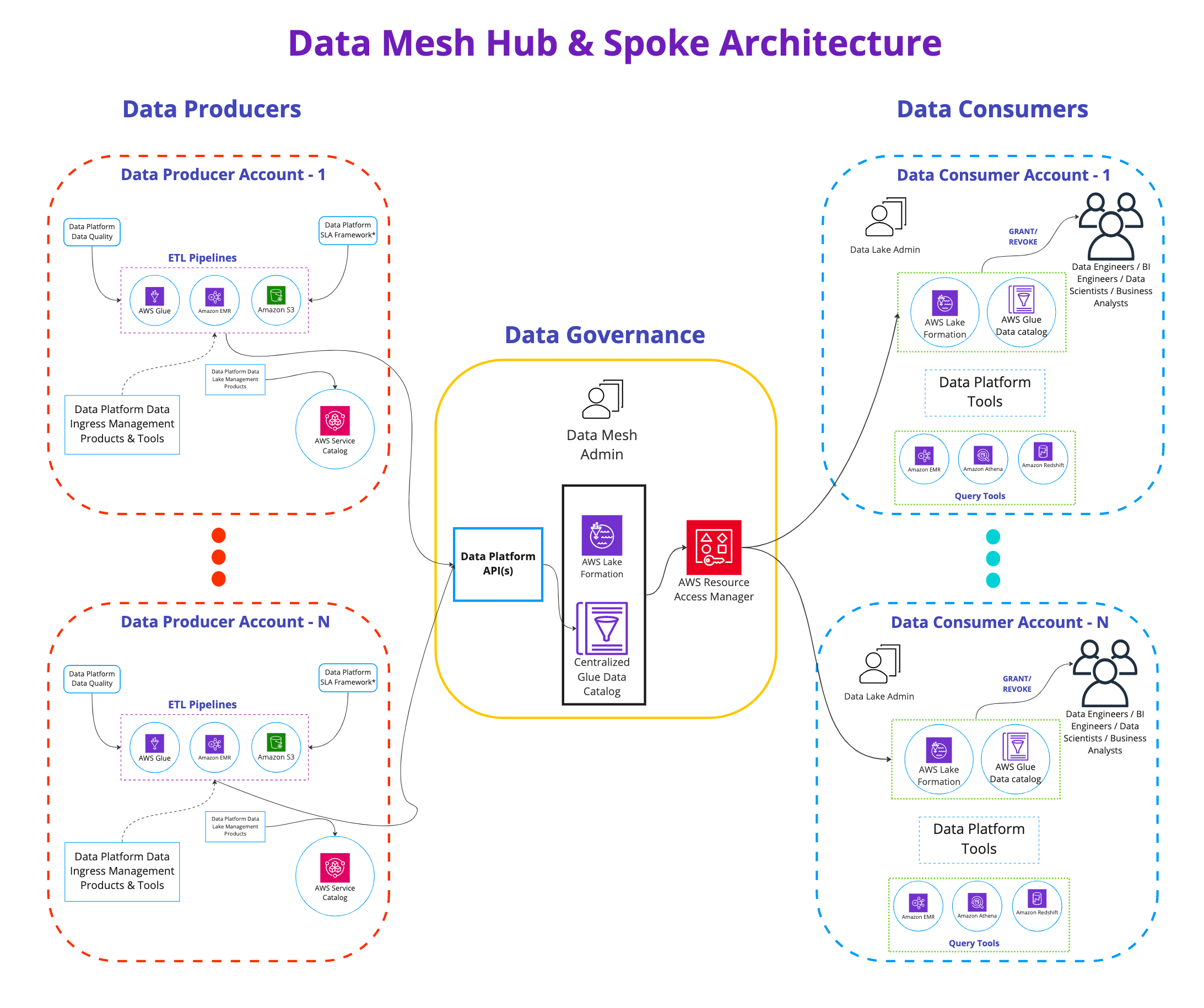
All these challenges with our Hadoop infrastructure motivated us to build a data mesh hub and spoke model, using a central data catalog containing information about all the data products that exist in the company. In AWS terminology, this is the AWS Glue Data Catalog. The Data Platform team provides APIs, SDKs, and Airflow Operators as components that different teams use to interact with the catalog. Activities like updating the metastore to reflect a new partition for a given data product, and occasionally running MSCK repair operations, are all handled in the central governance account. Lake Formation is used to secure access to the Data Catalog.
The Data Platform team introduced a layer of data governance that ensures best practices for building data products are followed throughout the company. They provide the tooling to support data engineers and business analysts while leaving the domain experts to run their data pipelines. With this approach, we have well-curated data products that are intuitive and easy to understand for our business analysts.
A data product refers to an entity that powers insights for analytical purposes. In simple terms, this could refer to an actual dataset pointing to a location in Amazon Simple Storage Service (Amazon S3). Data producers are responsible for the processing of data and creating new snapshots or partitions depending on the business needs. In some cases, data is refreshed every 24 hours, and other cases, every hour. Data consumers come to the data mesh to consume data, and permissions are managed in the central governance account through Lake Formation. Lake Formation uses AWS Resource Access Manager (AWS RAM) to send resource shares to different consumer accounts to be able to access the data from the central governance account. We’ll go into details about this functionality later in the post.
The following diagram illustrates the solution architecture.
Phase IV: Unified Data Platform (2023 - future)
The journey towards a modern, low-cost cloud data platform at GoDaddy was not without challenges. After migrating to AWS and adopting a data mesh architecture, the team encountered fragmented experiences, disconnected systems, and a large amount of technical debt. These challenges spanned across technical intersections and encompassed the need for a unified customer experience the integration of disparate systems into a single, unified view for customers and users.
In early 2022, the Data Platform team at GoDaddy took a deep dive into their systems to address these challenges and develop a future-focused solution that would support the company’s goal of “Data- as -a -Service.” This involved considering how the various big data systems would interact with each other and how to enable access for hundreds of internal GoDaddy employees and millions of entrepreneurs worldwide.
To solve these challenges, the team came together to develop the Unified Data Platform. This platform is designed to be forward-looking, well- integrated, and customer-centric, ensuring a seamless and efficient experience for all users. By addressing the obstacles faced during the journey, the team has created a robust and effective solution that will support the ongoing success and growth of GoDaddy and its customers. The following diagram outlines the Unified Data Platform’s architecture.
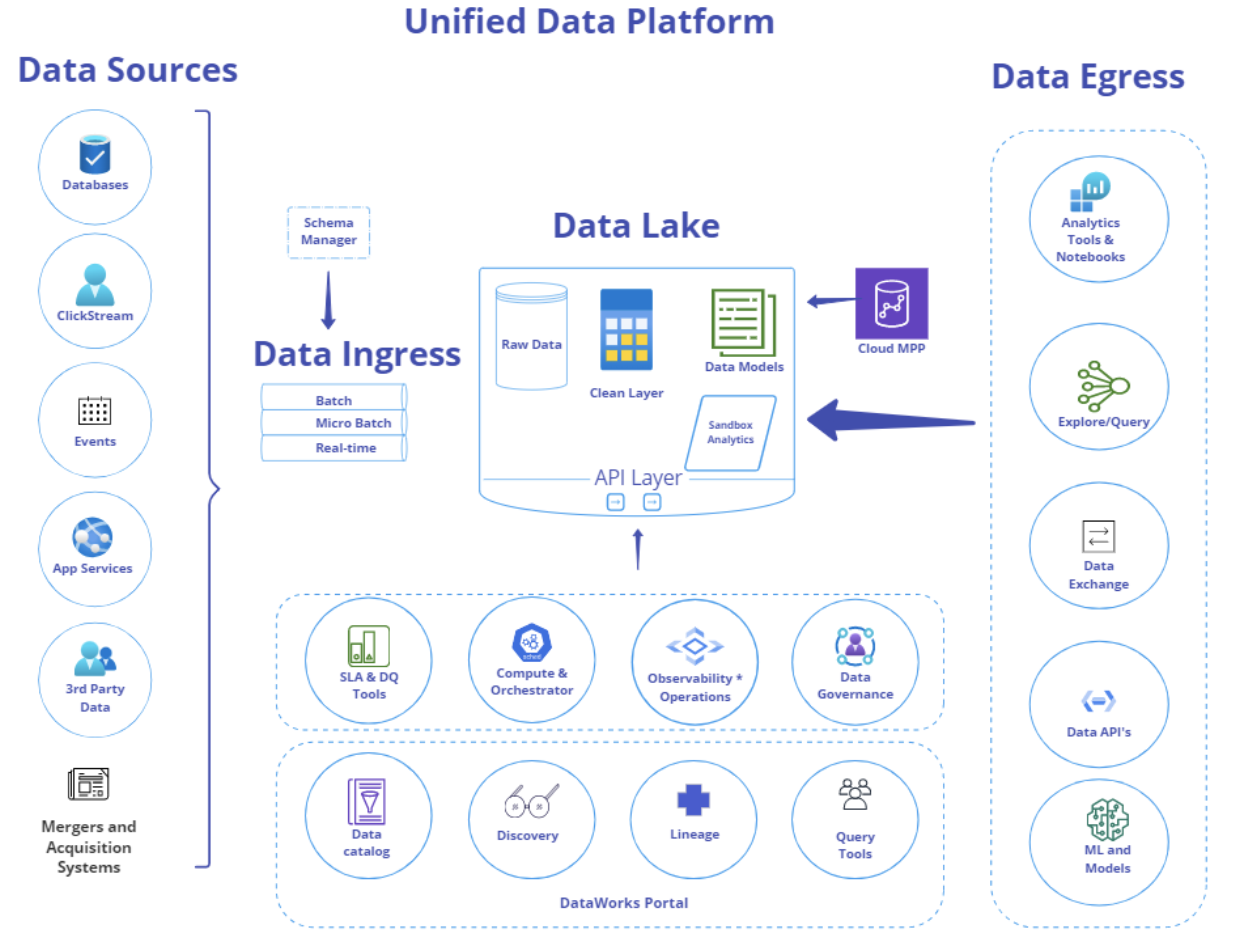
The modern data platform at GoDaddy has several key benefits that enhance the overall experience for business analysts, customers, and the internal GoDaddy team. Some of these benefits include:
- Streamlining the business intelligence development lifecycle: Migrating Alation and Tableau to the cloud and the adoption of DevOps operational excellence and secure tooling has reduced friction and time for business analysts to produce new insights, improving their productivity.
- Improved productivity: Optimizing compute costs and infrastructural overhead has improved productivity by 10 times, allowing the team to focus more on high-value tasks.
- Elevated customer experience: Designing the platform with improved ingress patterns, search, discovery, understandability, trust, and the abstraction of complexity in areas of compute and orchestration has provided a superior customer experience.
- Modernized customer signal capture: Adopting ABC schema standards for customer signal capture has enabled the reliable stitching of customer journeys and self-serve onboarding through the control plane.
These benefits have allowed GoDaddy to provide a seamless, efficient, and reliable data processing experience for its customers and internal team, supporting the company’s goals for data-as-a-service.
Go Daddy is focused on building authentic customer relationships and believes that data is at the core of delivering high-quality customer experiences. The company aims to minimize the unit cost of customer value delivered, accelerate time to value and simplify processes. Go Daddy is investing in ways to minimize the costs of running both mission-critical and ad-hoc workloads. The company is working to enable self-service while paying close attention to data governance and making platform adoption simple. Go Daddy is also moving at a fast pace to capture signals and deliver them in a safe and trustworthy way for near real-time understanding of customers and the business. The platform is built to recognize the roles of Business Analysts, Data Engineers, Data Scientists, and Product and eliminate wasteful work to accelerate insights.
What’s Next:
In the near future, the data platform has several exciting initiatives in progress or in its product backlog. One of the priorities is to improve operational efficiency for data consumers through internal data certifications, such as SQL training. Another important initiative is the launch of “DataWorks,” a one-stop shop experience that will simplify the process of searching, discovering, and processing data.
We are also building new Compute & Orchestration platform, to reduce the complexity of computing and debugging low-performing big data apps, while also minimizing high-compute costs through shared best practices and simplified configurations. The platform aims to increase trust in data, minimize time to insight, and maximize productivity for data scientists and business analysts.
Additionally, the data platform will enable self-serve data models and machine learning platforms to enhance engagement, retention, and acquisition of customers through personalized strategies, cross-selling, and upselling. The platform is also working towards a near-real-time view of order data and will establish a new DevOps team to support service operations and infrastructure initiatives. The new DevOps team will drive productivity gains and telemetry will be used to analyze results and guide further improvements. An additional function around operational efficiency has also been set up to further support these initiatives.
We look forward to sharing the continuation of our journey in the second part of our technical blog in the future.





