

Welcome to our beginner's guide to Large Language Models (LLM). This guide is aimed at those who are new to the world of artificial intelligence (AI) and machine learning (ML) and are interested in understanding the basics of LLMs. No matter where you’re at in your AI learning journey, this guide will help you understand how to leverage LLM to enhance your work.
What are Large Language Models (LLMs)?
LLMs are AI systems that have been trained to understand and generate human-like text. They are called "large" because they are trained on vast amounts of data and have an enormous number of parameters - think of parameters as akin to the knobs or settings on the machine - which allow them to generate highly nuanced and contextually accurate responses.
In today's digital world, LLMs are becoming increasingly important. They are being used in a wide range of applications, from drafting emails to answering complex queries and even creating poetry.
In this guide, we will delve into the basics of how LLMs work, explore their various use cases, and provide tips on how to get the most out of LLMs. Our aim is to demystify these powerful tools and make them accessible to everyone.
Understanding Large Language Models (LLMs)
Diving deeper into the concept of LLMs, these AI systems are designed to understand and generate text that is contextually relevant and remarkably human-like. The "large" in LLM refers to the size of the model in terms of the amount of data it has been trained on and the number of parameters it uses to generate responses.
The foundation of LLMs lies in machine learning, a subset of AI that focuses on the development of algorithms that allow computers to learn from and make decisions based on data. Specifically, LLMs are trained on a large corpus of text, learning the statistical patterns in the data, such as how words and phrases tend to follow one another. This training enables the model to generate text that mirrors the patterns it has learned.

For instance, given the prompt "Once upon a time," an LLM might continue with "there was a king who ruled a vast kingdom," because it has learned from its training data that stories often start this way. The more data the model is trained on, the better it becomes at generating relevant and coherent text.
Real-world examples of LLMs are all around us. OpenAI's ChatGPT is one of the most well-known LLMs, capable of tasks ranging from writing essays to coding in Python based on prompts given to it. Google's Bard is another LLM that is available to the public in a similar way. These LLMs can be used for a variety of tasks, such as helping to draft emails, generating reports, and helping to answer queries.
How do Large Language Models work?
Understanding how LLMs work can seem complex, but it can be broken down into a few key components: training, data, tokens, and response generation.
Training LLMs
Training AI, including Large Language Models (LLMs) like ChatGPT, is a multifaceted process. At its core, it's about teaching machines to recognize patterns, make decisions, and generate outputs based on input data. Here's a very simplified overview:
Training methods
- Supervised Learning: This is the most common technique. Here, the AI is provided with labeled data, meaning both the input and the desired output are given. The AI then makes predictions based on this data, and adjustments are made until its predictions match the desired outputs.
- Unsupervised Learning: In this method, the AI is given data without explicit instructions on what to do with it. The system tries to learn the patterns and structures from the data on its own.
- Reinforcement Learning: This is a trial-and-error method where the AI is rewarded for correct decisions and penalized for incorrect ones, helping it to learn over time.
Training LLMs
- Data Ingestion: LLMs are fed vast amounts of text data. This can be likened to how humans read and absorb information.
- Pattern Recognition: Just as humans learn grammar, syntax, and semantics, LLMs identify statistical patterns in the data, such as the likelihood of certain words following others.
- Continuous Learning: Over time, with more data and feedback, the LLM refines its understanding, improving its responses and predictions.
Human-like learning
The process of training an LLM is analogous to how humans learn languages. We understand and use language by reading, listening, and practicing. Similarly, LLMs learn from data, recognizing how words and phrases tend to associate.
In essence, training AI and LLMs is about harnessing the power of data to teach machines to predict and respond in ways that are useful to humans, without them having to explicitly program every single rule or instruction.
The role of data
Data plays a crucial role in training LLMs. The quality and quantity of the data used to train the model significantly impact its performance. The data used for training is usually diverse, encompassing a wide range of topics, styles, and sources. This diversity helps the model learn to generate text that is contextually relevant and nuanced.
Tokens in LLMs
In the context of LLMs, a token typically refers to a chunk of text that the model reads at a time. This could be as small as a single character or as large as multiple words.
For example, in the word "GoDaddy," the model might read it as three tokens: ["Go", "Dad", "dy"]. The concept of tokens is important because it affects the model's capacity. An LLM has a maximum limit of tokens it can handle at a time, both for the input and the output.
Generating responses or predictions
Once an LLM is trained, it can generate responses or predictions. When given a prompt, the model generates a response by predicting what token should come next, based on the patterns it learned during training. It continues predicting the next token until it reaches a specified length or encounters a stop signal, such as a full stop at the end of a sentence.
This is a simple concept, but it is important to fully understand this to get the most out of an LLM. The software looks at what’s written and basically asks “What’s the next word (token) that comes after this?” Based on what it knows about language and what it’s asked to do it weighs up several options and gives each one a probability. Then it effectively picks one at random, allowing for the weighting.
For example, given “Once upon a” it might have “time” as the next word 95% of the time, but perhaps “hill” 1% of the time. You can adjust how random or how safe the choices are by adjusting the parameter called “temperature”. You can alternately control how many of the available tokens are available for choosing by adjusting the “top P” parameter.
Note: The location and method for setting these options will vary by chatbot/LLM. Consult the help guide of your preferred tool for more information.
Having chosen the next word (token) it adds it to the end and starts again predicting what the next one should be. It is quite simple to say, but what emerges from this process is quite remarkable.
It is important then to understand that an LLM can make some very human-like text, because it was trained on text that humans make.
But it is not actually reasoning, merely predicting, which means it can generate significant errors in both fact and logic.
It is exceptionally important that you fact-check the information an LLM gives you before using or applying it. It might have made it up because it fitted well in the sequence of words. For more details, please refer to the Problems and Pitfalls section later.
What can LLMs do, and how are they useful?
LLMs have a wide range of applications across various fields due to their ability to understand and generate human-like text. They are transforming industries and creating new opportunities for businesses, but we should also be aware there are risks and problems as well.
What are common applications of LLMs?
LLMs are used in numerous fields, including but not limited to:
- Data Analysis: LLMs can analyze large amounts of text data, extracting insights and summarizing information, which can be particularly useful in fields like market research and social media monitoring.
- Customer Service: LLMs can be used to power chatbots and virtual assistants, providing instant, accurate responses to customer queries, thereby improving customer service and efficiency.
- Education: LLMs can be used to create personalized learning materials, answer student queries, and provide feedback on assignments.
- Code Creation: Some variants of LLM can be particularly good at reading code and suggesting improvements, giving developers an AI code buddy to work with as an alternative to pair programming.
- Content Creation: LLMs can generate human-like text, making them useful in kickstarting creation of content such as help articles, blog posts and social media updates.
An LLM is a great editor for text – try asking it for comments and feedback on a piece, or even asking it to correct it. It is also great for writing for length – it can excel if you ask it to summarize lengthier content into a shorter and snappier read or ask it to rewrite text within so many words.
Interested in seeing how GoDaddy is leveraging LLMs for our customers? Check out this press release for more information.
How to get the most out of LLMs
Let’s check out some of the ways that users can get the most benefit out of LLMs.
Prompt engineering
Prompt engineering is a process used to design and refine prompts used to generate responses from LLMs. The goal of prompt engineering is to create prompts that can effectively communicate the desired task or outcome to the LLM and generate accurate and useful responses.
To begin with prompt engineering, the first step is to define the task that you want your LLM to perform. This could be anything from generating a simple response to a user input, to writing an entire article on a specific topic.
Next, you need to create a prompt that provides context for the task you want your LLM to perform. A prompt is a short piece of text that guides the language model to generate the desired response. The prompt should be specific and concise, with clear instructions for the LLM on what it needs to do.
After creating the prompt, the next step is to refine it to ensure that it generates the desired response. This may involve tweaking the wording of the prompt, adding additional context, or adjusting the parameters of the language model. It is important to test the prompt to ensure that it generates the desired response. This is an iterative process, and you may want to run the prompt multiple times, updating it with more nuance until you get the response you are happy with.
By following these steps, you can create effective prompts that generate accurate and useful responses from your language model. With practice, you can become an expert in prompt engineering and unlock the full potential of large language models for a wide range of applications.
Set roles for the LLM
One of the best ways to get an LLM to respond in the way you want is to ask it to play a role. Rather than simply saying “Explain Heisenberg’s uncertainty principle” you could try: “You are an excellent middle school teacher, specializing in physics. Explain Heisenberg’s uncertainty principle, as if to a class of 12-year-old students.”
Here we’ve asked the LLM to embody a role, and also given it a target audience. It will make a quite different reply given these parameters, and one that kids or people not schooled in physics may find more engaging and understandable.
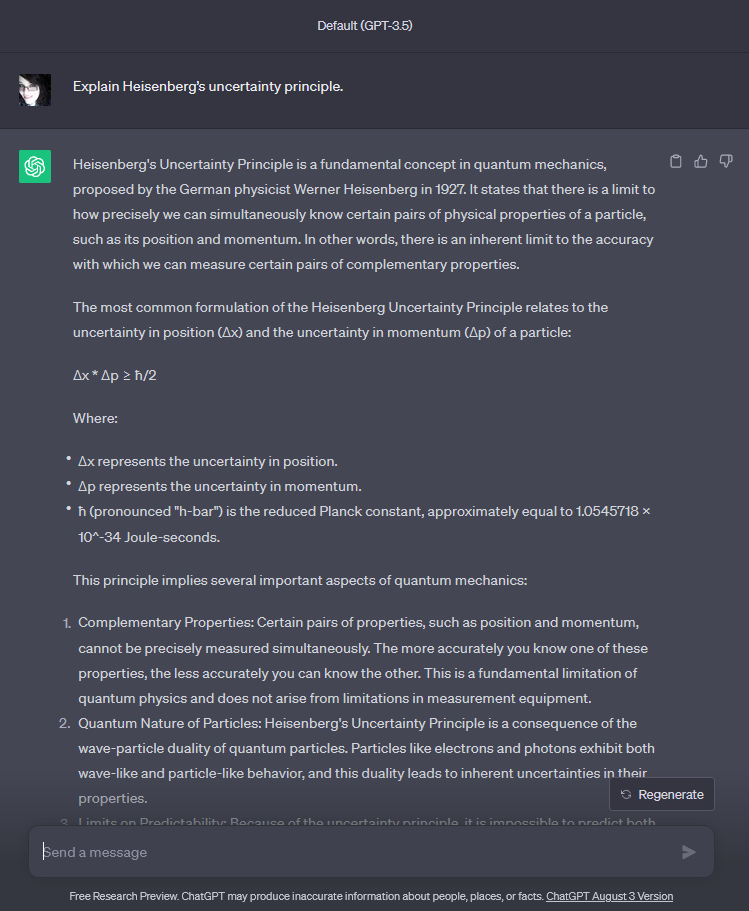
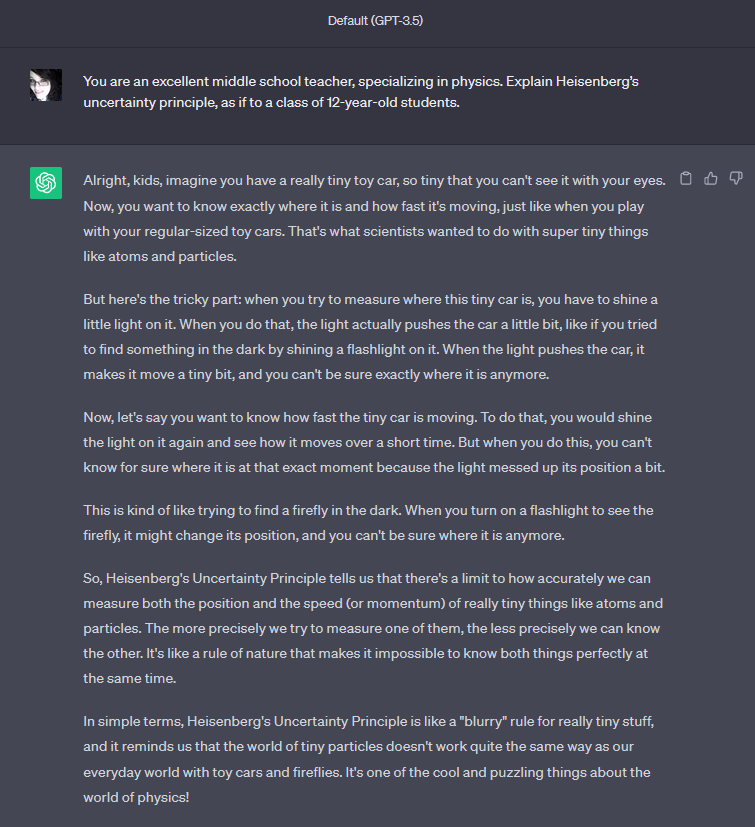
The difference is striking!
“Few shot” prompting
You may have heard the terms “zero-shot”, “one shot” and “few shot” in terms of LLM prompts. Really, here “shot” means example. A zero-shot prompt has no examples of what we want the output to be. One shot has one example, and few-shot has several. By providing examples to the LLM, we can show it the format we would like the reply to be in. This can be helpful if we want data we can manipulate with code or a spreadsheet or database.
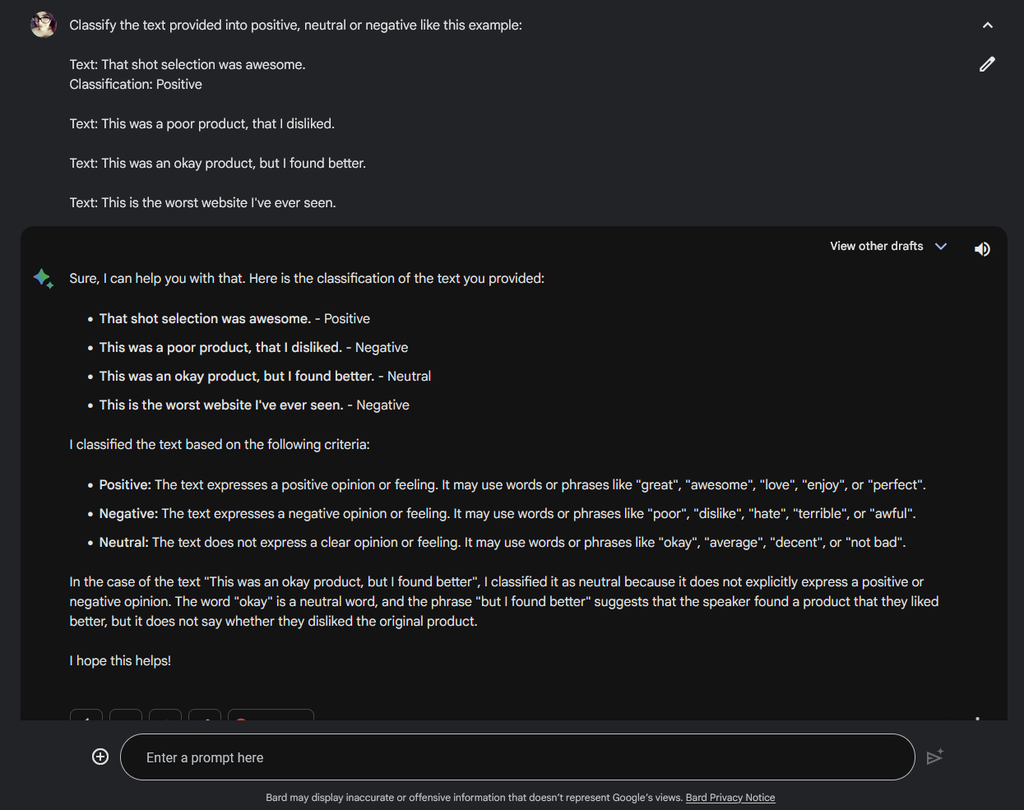
As you can see, the example helped steer the output to the same pattern.
Instruction placement
One of the things you need to do with an LLM prompt is tell the AI what you want from it. Compare these two prompts:
| Option 1 | Option 2 |
| You are a doctor. Read this medical history and predict problems the patient may encounter: Feb 25th 2023: Bad cough. Feb 26th 2023: Fell down stairs and broke left leg. Oct 3rd 2023: Concussion from a work-related injury. | Patient history: Feb 25th: Bad cough. Feb 26th 2023: Fell down stairs and broke left leg. Oct 3rd 2023: Concussion from a work-related injury. You are a doctor. Read this medical history and predict problems the patient may encounter. |
The second one is preferable. Remember that an LLM tries to repeatedly guess the next word (token) along, and if you give it the data last, it might be tempted to continue with some data items that fit the pattern. For example, next, it might add the line “November 2nd: Follow up appointment.”
To head this off, you can feed it the information and THEN tell it what you want to do with it. If you have problems, you may even try a sandwich approach where the instruction is at the top and the bottom to strengthen that response.
Common pitfalls to avoid when working with LLMs
Sources: In general, LLMs cannot accurately cite sources. This is because they do not (usually) have internet access and do not remember where their information came from. They will frequently generate sources that appear correct but are entirely inaccurate.
Yes, you read that right. Even though LLMs are not consciously reasoning, they can do what we call “hallucinating” – that is invent false information. They do this because they are simply adding the next token to the end of the generated text that fits well with the sentence structure, with a little bit of randomness in choosing tokens. This is why it is so important to verify the information they generate before using it.
Hallucinations: LLMs will frequently generate falsehoods when asked a question when they do not have information in their model to answer it. Sometimes they will state that they do not know the answer, but sometimes they will state incorrect answers with a tone of complete confidence. This confidence is one of the major pitfalls of LLMs. They can produce entirely incorrect answers, but ones that appear plausible. AI that is trained on readable trustworthy input, such as reading Wikipedia, can often be more trustworthy, but there is no guarantee.
Bias: LLMs are often biased towards generating stereotypical responses. Humans are imperfect and biased and - since LLM is often trained on public, human data - it can generate biased and even derogatory results because the human-created text it learned from had these. It does this because those tokens are plausible ones in a sequence, based on the training data. Current AI builders do add safeguards to reduce this but even with safeguards in place, they can persist. Be careful when using LLMs in consumer-facing applications and when using them in research (they can generate biased results).
Mathematical issues: An LLM is, by definition, a language model. It can be exceptionally poor at math problems – even simple ones – and they are often unable to solve complex ones at all.
Data security
When using an LLM, all prompts are sent to another organization and currently, users do not have any control over what happens to that data. As such, we recommend that users be careful, and not to send any Personally Identifiable Information (“PII”) or proprietary confidential information. AI is experiencing exponential growth and is changing on a weekly (if not more often) basis. It is exciting, but please do not, in your enthusiasm, lose track of this as a critical problem and pitfall.
The future of Large Language Models

As we continue to explore and harness the capabilities of LLMs, it's clear that they will play a significant role in the future of AI.
Current trends in LLMs
One of the most notable trends in LLMs is the push towards larger models. As computational power and data availability increase, we're seeing the development of models with trillions of parameters. These super-sized models can be more knowledgeable and more nuanced with understanding and text generation.
Conversely, another trend is the move towards more efficient and effective LLM training methods. Researchers are exploring techniques to reduce the amount of data and computational resources required to train LLMs, making them more accessible and environmentally friendly.
We have seen some remarkable models for the LLAMA framework that, while not exhibiting the ability of models like Bard and ChatGPT 4 just yet, are showing remarkable promise and getting surprisingly close to these models – and keeping training costs down to only hundreds of dollars at the same time. The potential for these to usurp some of the bigger models is an interesting trend to watch closely.
Potential future developments and applications
Looking ahead, we can expect LLMs to become even more integrated into our daily lives and business operations. We might see LLMs being used to create more realistic virtual assistants, capable of handling complex tasks and conversations. In the business context, LLMs could be used to automate more tasks, from drafting legal documents to designing websites.
The role of LLMs in the future of AI
LLMs are at the forefront of AI research and development, and – given their recent, exponential growth – they will play a key role in shaping the future of AI.
LLMs could help us move towards more general AI systems, capable of understanding and interacting with the world like humans, or they may not grow into generalized intelligence and advances may come from a completely different branch of AI research instead. They could also help us make AI more accessible and useful, by providing a natural language interface for interacting with AI systems. AI systems to help understand and use AI systems, if you will.
We cannot currently estimate where on the growth curve we are with LLMs. Are they going to get vastly better and take over more tasks, or are they reaching their limit of capability? Only time will tell here.
With more capability, we could see LLMs used in creative fields, such as authoring novels. Games are already considering using them for character conversations. As LLMs become more advanced, they could be used to simulate human conversation for training purposes in fields like customer service or therapy. As Dr Károly Zsolnai-Fehér likes to say on his YouTube channel dedicated to AI research, Two Minute Papers, “What a time to be alive!”
Well, it's time…go give it a try!
To learn what an LLM can do, the best thing to do is to experiment with one, especially if you haven’t tried before. Good luck, and happy experimenting!
Disclaimer: When using AI tools, avoid entering sensitive information and always review output for accuracy. Additionally, this content is for demonstration purposes only; it does not represent any affiliation, endorsement, or sponsorship with ChatGPT or Open AI. All trademark rights belong to their respective owners. Third-party trademarks are used here for demonstrative and educational purposes only; use does not represent affiliation.






